Introduction
Are you ready to have your mind blown? I'm Erick Wendel, and I've recreated the Node.js project from scratch, uncovering some shocking truths along the way, and published it on my Youtube channel.
Think you know everything about Node.js and JavaScript? Think again.
In this post, I'm going to reveal the top 5 myths about Node.js that you thought you knew but didn't.
Get ready for some mind-bending concepts that will change the way you think about this powerful JavaScript runtime.
From uncovering hidden features to debunking common misconceptions, I'm gonna separate fact from fiction and unleash the truth.
Get ready to have your mind blown as I separate fact from fiction and unleash the truth about this powerful JavaScript runtime.
Are you ready? Grab a drink and let's begin!
Attention! Before we dive into this mind-blowing video, make sure you hit that subscribe button and join my Telegram channel.
Why? Because I don't want you to miss out on any of the incredible topics I'll be covering in the future. Trust me, you won't want to miss a single one.
And if you're feeling extra supportive, show some love by giving this post a thumbs up and leaving a comment below with your suggestions for what you wanna see next.
Your support means everything to me, and I'm committed to bringing you the best tech content out there.
So, thank you for choosing to read my post, and get ready to be blown away.
Let's do this!
1 - setTimeout, setInterval, and console are not JavaScript
The functions setTimeout, setInterval, and console are not JavaScript, they're in fact functions that every runtime implements by convention.

It's part of a working group that defines a common Standard API for all runtimes to follow it.
Node.js and the C++ bridge between JavaScript, V8, and Libuv
Node.js is a tool that extends Chrome's V8 engine behavior by adding functions and making the job schedule async functions to Libuv.
The video below I made explains how to introduce custom print and setTimeout functions to a JavaScript runtime.

In short terms the workflow is:
JavaScript is just a string that will be interpreted and executed by Chrome's V8 engine.
The C++ code is a bridge between JavaScript, V8, and Libuv. There you can add a new function to the global JavaScript context by using the V8 API.
After writing the code that adds a new function to V8 (such as "print"). It'll magically be available to call it from JavaScript from the globalThis.
Implementing a custom console.log function
In Node.js for example, a console.log function is just an abstraction to the C++ printf function. Check out the code below (and the full version here).
static void Print(const v8::FunctionCallbackInfo<v8::Value> &args)
{
bool first = true;
for (int i = 0; i < args.Length(); i++)
{
v8::HandleScope handle_scope(args.GetIsolate());
if (first)
{
first = false;
}
else
{
printf(" ");
}
v8::String::Utf8Value str(args.GetIsolate(), args[i]);
printf("%s", *str);
}
printf("\n");
fflush(stdout);
}
The example above is part of the code snippet I used in my tutorial recreating Node.js to show how a console.log is implemented there.
It's a C++ function that is bound to the JavaScript global environment and then you can call it from a JavaScript function.
print('Hello World')
So when you call this specific function from your JavaScript code it magically works as if it was part of JavaScript.
On Chrome, it's an internal function on the browser. The same happens to all other browsers or JavaScript runtimes.
The setTimeout and setInterval follow the same approach. They're C++ functions and in Node.js Libuv is responsible for handling timers.
Timers rely on the environment and anything that you call from JavaScript that relies on the environment usually is an external function.
In Node.js, setTimeout and setInterval are abstractions to the Libuv timers which make internal calls to the Operating System APIs.
The example below shows a C++ code snippet used to create setTimeout and setInterval functions from my tutorial.
static void Timeout(const v8::FunctionCallbackInfo<v8::Value> &args)
{
auto isolate = args.GetIsolate();
auto context = isolate->GetCurrentContext();
int64_t sleep = args[0]->IntegerValue(context).ToChecked();
int64_t interval = args[1]->IntegerValue(context).ToChecked();
v8::Local<v8::Value> callback = args[2];
if(!callback->IsFunction())
{
printf("callback not declared!");
return;
}
timer *timerWrap = new timer();
timerWrap->callback.Reset(isolate, callback.As<v8::Function>());
timerWrap->uvTimer.data = (void *)timerWrap;
timerWrap->isolate = isolate;
uv_timer_init(loop, &timerWrap->uvTimer);
uv_timer_start(
&timerWrap->uvTimer,
onTimerCallback,
sleep,
interval
);
}
Check out the full code here.
All features that exist in JavaScript are defined by the ECMAScript specification. Anything apart from it would be specific to the execution environment JavaScript is being executed.
This means that if Node.js wanted to call it print instead of console.log it wouldn't have been breaking the ECMAScript specs.
2 - Promises are not async ops, just wrappers for callbacks

Promises are in the JavaScript spec! This means they would never depend on the environment in which JavaScript is being executed.
The common misconception is to think that Promises are asynchronous operations.
Promises are a way to handle asynchronous operations and provide a mechanism for handling the results of those operations once they're completed.
They allow you to write asynchronous code that looks and behaves like synchronous code, making it easier to read and maintain.
Promises are designed to work specifically with asynchronous code.
When you create a promise, you're essentially saying "this operation might take some time to complete, but when it does, here's what I want to do with the result."
They're just an abstraction for making it easier to work with callbacks internally.
const setTimeout = (ms, cb) => timeout(ms, 0, cb);
const setInterval = (ms, cb) => timeout(0, ms, cb);
const setTimeoutAsync = (ms) =>
new Promise(resolve => setTimeout(ms, resolve));
; (async function asyncFn() {
print(new Date().toISOString(), 'waiting a sec....');
await setTimeoutAsync(1000);
print(new Date().toISOString(), 'waiting a sec....');
await setTimeoutAsync(1000);
print(new Date().toISOString(), 'finished....');
})();
The full code is here.
Check this out. In the code snippet above I created an object that wraps a callback function with a Promise Object. The timeout function was built on the C++ side and the Promise object is JavaScript.
The timeout function I created, the async function that schedules a function to be executed in the future receives a callback as a parameter.
In the C++ land that is executed when the timeout finishes looks like the example below:
static void onTimerCallback(uv_timer_t *handle)
{
timer *timerWrap = (timer *)handle->data;
v8::Isolate *isolate = timerWrap->isolate;
v8::Local<v8::Context> context = isolate->GetCurrentContext();
v8::Local<v8::Function> callback = v8::Local<v8::Function>::New(
isolate,
timerWrap->callback
);
v8::Local<v8::Value> result;
v8::Handle<v8::Value> resultr [] = {
v8::Undefined(isolate),
v8_str("hello world")
};
if(callback->Call(
context,
v8::Undefined(isolate),
2,
resultr).ToLocal(&result)
)
{}
}
Full code here.
So the C++ function will call the given callback function and then on the JavaScript side, it'll call the resolve function so you can resolve it using async/await keywords to handle results once they're completed.
const setTimeout = (ms, cb) => timeout(ms, 0, cb);
const setInterval = (ms, cb) => timeout(0, ms, cb);
const setTimeoutAsync = (ms) =>
new Promise(resolve => setTimeout(ms, resolve));
await setTimeoutAsync(1000);
print(new Date().toISOString(), 'waiting a sec....');
Now you know why simply putting a for loop inside a Promise object doesn't make it asynchronous.
What makes asynchronous operations in Node.js is Libuv calls.
3 - JavaScript is not a single-threaded or multithreaded language
JavaScript is grammar. It's what the V8 Engine uses to translate a string to C++ object instances.
Threading is an operating system concept which means it depends on which environment you're executing your code.
That's why if you want to use threading on browsers you use Web Workers API and on Node.js you use the Worker Threads module.
Two different approaches and two different APIs. Not related to the language at all.
Brief Announcement
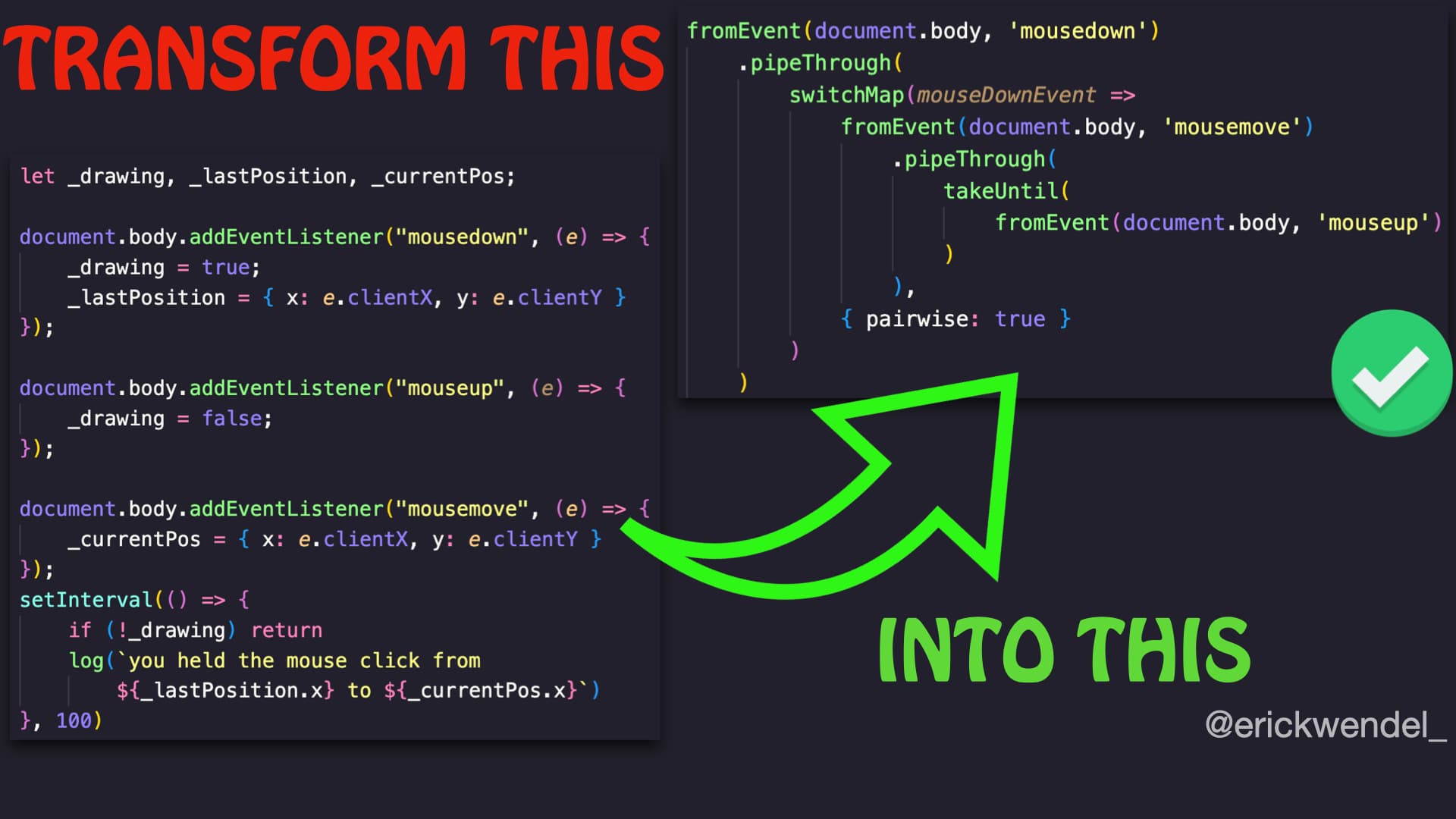
Just a quick break. I've released my first training course in English and it's been amazing! It's an advanced JavaScript content focused on JavaScript Streams.

As the only course on the market that covers JavaScript Streams in-depth, this training program is unlike anything you've ever seen before.
From the basics to advanced concepts, you'll explore every nook and cranny of this powerful tool, unlocking its full potential and discovering how it can change how you write JavaScript code.
With this course, the sky's the limit! Check this page for full info on the training.
Also, follow me on Instagram, Twitter, and LinkedIn, and check out my website where I gather all the training courses I've launched.
There's a lot of information that can help you, and of course, a lot of free content for you.
Some folks were complaining that Node.js wasn't multi-threaded.
However, as the Node.js docs guide tells us, It's been using a Thread Pool since day one.
The thread pool, also known as the Libuv Worker Pool, has a bunch of threads that are used to handle heavy tasks like file System APIs, Cryptography, and DNS.
The thing is, these threads were only used internally in the runtime, and it wasn't available until recently that the Worker Threads module was added to the Public Node.js API.
So, now developers can use them in their own applications and take advantage of Node.js' multithreading capabilities.
Overall, Node.js is a beast of technology that can handle pretty much anything you throw at it.
And with the thread pool and Worker Threads module, it's got even more muscle to flex.
5 - The Event Loop is Single Threaded and that's what makes it special
Back in 2009, the world of web development was exploding with new technologies and frameworks emerging left and right.
At the time, languages such as Java and C# were popular choices for building web applications.
However, they had a significant drawback when it came to handling large numbers of concurrent users.
These languages used a blocking I/O model and heavyweight threads to handle individual requests, which often led to performance bottlenecks and memory issues when dealing with multiple concurrent connections.
To handle many concurrent users, these languages would reserve a large amount of memory, causing servers to use 80% of the available memory most of the time.
When usage spiked, they would quickly reach 100% and had to scale up rapidly.
Moreover, threading had to be carefully managed to ensure that two operations wouldn't change the same memory address at the same time, a problem known as Dead Lock.
In this rapidly changing landscape, a new technology emerged that promised to tackle these issues and revolutionize web development as we knew it.
This technology was Node.js.

Image of the first Node.js version (v.0.0.1)
Node.js was designed from the ground up to handle large numbers of concurrent connections and real-time web applications.
With Node.js, developers could build real-time web applications that were more scalable, efficient, and responsive than ever before.
In a world where web development was constantly evolving, Node.js became a shining beacon of innovation and change.
It allowed developers to tackle the challenges of concurrency head-on and build applications that could handle the demands of modern users with ease.
The Node.js concurrency model is game-changing as it doesn't need to reserve memory for each client.
Node.js Concurrency model highlights
The Node.js concurrency model, which is based on an event-driven, non-blocking I/O model, was considered better than the popular concurrency models back in 2009 for several reasons:
Non-Blocking I/O
Unlike traditional languages, Node.js used a non-blocking I/O model and lightweight event loops to handle requests.
This allowed it to handle a large number of concurrent connections without blocking the execution of other tasks and without consuming excessive memory.
This is in contrast to the blocking I/O model, which can lead to performance bottlenecks when handling multiple concurrent connections.
Lightweight processes
Node.js uses lightweight processes (known as "event loops") to handle requests, which are more efficient than the heavyweight threads used by C# and Java. This allows Node.js to handle a larger number of requests with less overhead.
Asynchronous programming
Additionally, Node.js encouraged asynchronous programming, which allowed developers to write more efficient and responsive code that could handle multiple tasks in parallel without blocking the main thread.
Real-time web applications
Node.js was designed specifically for building real-time web applications, which require a high degree of concurrency and low-latency communication between the server and client.
Overall, the Node.js concurrency model was seen as a more efficient and scalable solution for handling concurrent connections and real-time web applications compared to the popular concurrency models back in 2009.
Thanks for reading
That's it for today. Let me know in the comments which of the things I told you today has impressed you the most.
And if you want to see more content like this, keep an eye on the blog and of course, subscribe to my Youtube channel.
I hope this content has exceeded your expectations.
I'm Erick Wendel and I'll see you in the next post!